


Google Colab上でYOLO v3を使って、手持ちの画像の物体検知をしてみた
ディープラーニングの画像処理の勉強のため、YOLO v3で手持ちの画像の物体検知を試みます。Google Colaboratory上でYOLO v3を入れて、サンプル画像で物体検知しました。それから、手持ちの画像をGoogle Colaboratoryにアップロードして、その画像をYOLOで物体検知してみました。

概要
ディープラーニングの画像処理の勉強のため、YOLO v3で手持ちの画像の物体検知を試みます。
まずGoogle Colaboratory上でYOLO v3を入れて、サンプル画像で物体検知しました。
それから、手持ちの画像をGoogle Colaboratoryにアップロードして、その画像をYOLOで物体検知してみました。
行ったこととしては以下のようになります。
- Google Colaboratoryの設定
- YOLOのインストールし、サンプル動かす
- Google Colaboratoryで画像表示させる
- 手持ちの画像をGoogle Colaboratoryにアップロード
- 手持ちの画像をYOLOで物体検知
Google Colaboratoryの設定
Google ColaboratoryはGoogleが提供しているオンラインのJupyterノートブック環境です。
機械学習に必要な設定はすでにされおり、GPUも使えます。
しかも無料です。
はじめてGoogle Colaboratoryを使ったので、いくつか設定がありました。
すでにGoogle Colaboratoryを使っている場合は不要だと思います。
GPU
「ランタイム」 –> 「ランタイムのタイプを変更」をクリックし、ハードウェアアクセラレータをGPUに変更します。

これでディープラーニングの処理を動かしたときに、速く終わります。
ショートカットの設定
Google Colaboratoryではキーボードショートカットを設定ができます。
私は、「コードセルの追加」にCtrl + Lを割り当てました。
オートコンプリート(入力補完)はデフォルトで「Ctrl+SpaceまたはTab」が割り当てられてます。
YOLOのインストールし、サンプル動かす
オープンソースのCNNであるdarkentをcloneして、ビルドします。
%%bash
git clone https://github.com/pjreddie/darknet
cd darknet
make
YOLOv3のweightをダウンロードします。
%%bash
cd ./darknet
wget https://pjreddie.com/media/files/yolov3.weights
サンプルで入っている画像(giraffe.jpg)に物体検知をかけます。
%%bash
cd ./darknet/
./darknet detect cfg/yolov3.cfg yolov3.weights data/giraffe.jpg
次のような結果が表示され、predicition.jpgが出力されます。
data/giraffe.jpg: Predicted in 21.032178 seconds.
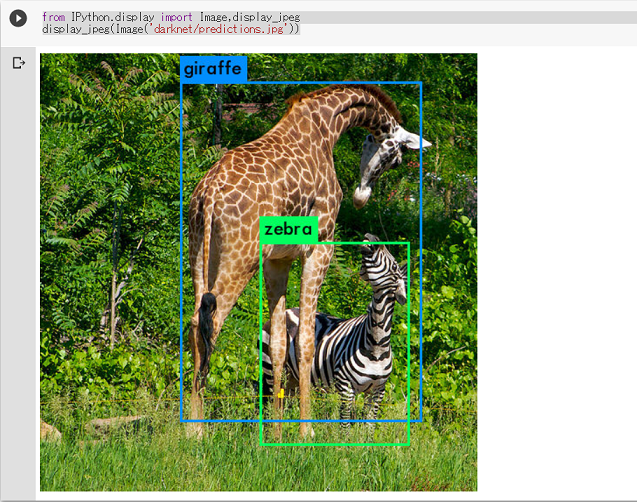
giraffe: 98%
zebra: 98%
Google Colaboratoryで画像表示させる
結果はprediction.jpgに出力されたのですが、Google Colaboratoryで画像の表示がわかりませんでした。
今回、IPythonを使って、画像を表示することにしました。
from IPython.display import Image,display_jpeg
display_jpeg(Image('darknet/predictions.jpg'))
実行すると、このような画像が表示されます。
正しく物体検知できていそうです。
手持ちの画像をGoogle Colaboratoryにアップロード
手持ちの画像をGoogle Colaboratoryにアップロードします。
Google Driveに画像を入れて、その画像をGoole Colaboratoryに入れます。
Google Driveに手持ちの画像を入れます。
それから、次のコマンドをGoogle Colaboratoryで実行して、Google Driveをmountします。
from google.colab import drive
drive.mount('/content/gdrive')
すると、Go to this URL in a browser: “URL” のように、”URL”が表示されるので、それをクリックします。
アクセス許可が求められるので、許可をクリック。
コードが表示されるので、それをコピーし、Google Colaboratoryのタブに戻って、Enter your authorization code: にペーストします。
Mounted at /content/gdrive と表示されたら、完了です。
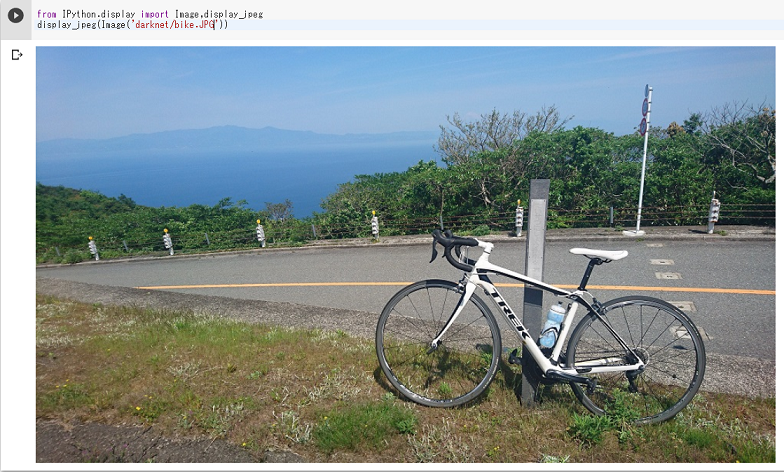
Google Driveに入れた画像を持ってきます。 今回は、bike.JPGを、/content/darknetにコピーします。
%%bash
cp gdrive/My\ Drive/bike.JPG darknet/
bike.JPGはこのような画像です。
手持ちの画像をYOLOで物体検知
Google Driveから持ってきたbike.JPGを物体検知にかけます。
調べたところ、Darknet YOLOでは物体検知にかける画像はリサイズしなくても、大丈夫なようです。
%%bash
cd ./darknet/
./darknet detect cfg/yolov3.cfg yolov3.weights bike.JPG
出力された結果は次のようになりました。
bike.JPG: Predicted in 20.956879 seconds.
bottle: 56%
bicycle: 100%
person: 94%
person: 86%
person: 65%
person: 64%
出力された画像を確認します。
from IPython.display import Image,display_jpeg
display_jpeg(Image('darknet/predictions.jpg'))

人と柱を誤認識している部分もありますが、物体検知は体験できました。
実行したコードはGitHubで公開しています。
https://github.com/KazumichiShirai/yolo-sample-python-notebooks

Share this post
Twitter
Facebook
LinkedIn